Data Linking Information Series
What is Data Linking?
Data linking is used to bring together information from different sources in order to create a new, richer dataset.
This involves identifying and combining information from corresponding records on each of the different source datasets. The records in the resulting linked dataset contain some data from each of the source datasets.
Most linking techniques combine records from different datasets if they refer to the same entity. (An entity may be a person, organisation, household or even a geographic region.)
However, some linking techniques combine records that refer to a similar, but not necessarily the same, person or organisation – this is called statistical linking. For simplicity, this series does not cover statistical linking, but rather focuses on deterministic and probabilistic linking.
Key Terms
- Confidentiality – the legal and ethical obligation to maintain and protect the privacy and secrecy of the person, business, or organisation that provided their information.
- Data linking – creating links between records from different sources based on common features present in those sources. Also known as ‘data linkage’ or ‘data matching’, data are combined at the unit record or micro level.
- Deterministic (exact) linking – using a unique identifier to link records that refer to the same entity.
- Identifier – for the purpose of data linking, an identifier is information that establishes the identity of an individual or organisation. For example, for individuals it is often name and address. Also see Unique identifier.
- Source dataset – the original dataset as received by the data provider.
- Unique identifier – a number or code that uniquely identifies a person, business or organisation, such as passport number or Australian Business Number (ABN).
- Unit record level linking – linking at the unit record level involves information from one entity (individual or organisation) being linked with a different set of information for the same person (or organisation), or with information on an individual (or organisation) with the same characteristics. Micro level includes spatial area data linking.
Why is data linking important?
Linked datasets create opportunities for more complex and expanded policy and research.
For example, data linking helped to identify the role of folate in pregnancy in reducing neural tube defects, such as spina bifida.
On the business front, in New Zealand, the Linked Employer-Employee Data (LEED) links taxation data with business data to provide information such as the employment outcomes of tertiary education and transitions from work to retirement and from benefit to work.
Data linking has the advantage of utilising information that already exists. Making use of data collections in this way avoids the time and expense of collecting a whole new set of data. It also avoids imposing extra questions on people and organisations when this information already exists.
What are the main ways to link datasets?
There are a number of different approaches to data linking.
Usually, the most straightforward way is to use a unique identifier (such as a tax file number) present on both files, in order to identify the links between the records on each dataset. This is sometimes referred to as ‘deterministic’ or ‘exact’ linking because the unique identifiers on the records either match or they do not – there is no uncertainty.
Where a unique identifier is not available, or is not of sufficient quality or completeness to be relied on alone, an alternative approach is to construct a linkage key, which acts as a proxy for the unique identifier. This key (or code) is created using identifiable information, such as name and address, available on both datasets.
Linkage keys can help to preserve privacy because the key replaces name and address, thereby reducing the chance of identification.
Probabilistic linking is another option for linking where a unique identifier is not available. Probabilistic linking is based on a calculation of the likelihood that a pair of records (one drawn from each dataset) refers to the same person/organisation. Complex methods and sophisticated data linking software are used to achieve high-quality results.
Protecting privacy and confidentiality of a linked dataset
Datasets that contain identifiable information need to be handled with care to protect the identity of a person or organisation. There is an increased risk of identification of an individual/business/organisation when two datasets are linked.
Even if identification is protected (such as by removing name and address) in the original datasets, the result of the linking may provide a combination of characteristics which leads to spontaneous recognition of the identity of a person or organisation (e.g., local area school data showing a cardiac specialist who is the mother of six).
To minimise this risk, data linking should only be conducted in a safe and effective environment ensuring that the methods used are fit-for-purpose. Confidentiality and statistical disclosure techniques are available to manage the privacy risks that can be associated with data linking
If a data linking project involves Commonwealth datasets and is for statistical and research purposes the project should comply with the High Level Principles for Data Integration Involving Commonwealth Data for Statistical and Research Purposes and the supporting governance and institutional arrangements.
Additional Sources of Information
- Christen, P. 2012, Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection, Springer, Canberra.
- NCSIMG 2004, Statistical Data Linkage in Community Services Data Collection, AIHW, Canberra.
- National Statistical Service 2011, Confidentiality Information Series, National Statistical Service, Canberra, Statistical Data Integration
- Statistical Data Integration (including the High Level Principles), see National Statistical Service at Statistical Data Integration
Significant effort is required to prepare datasets before they can be linked. Pre-linking preparation includes understanding the source dataset, selecting which fields to use for linking, data cleaning and standardising and, where required, secure data transfer.
It has been estimated that about three-quarters of the effort involved in data linking involves preparing the data to ensure the input files are ready for linking (Gill, 2001).
It is necessary to invest the time and effort in data preparation in order to ensure the quality of the linked dataset.
Understanding the source datasets
Before attempting linking, it is important to understand the information in the datasets being linked, to ensure the linking software is comparing ‘apples with apples’. This can be achieved in a number of ways, including examining the metadata and checking a sample of the dataset.
Metadata is information about data that provides context or additional information, such as how and when the data was collected, its purpose and quality.
Understanding the metadata helps to avoid combining data that is not compatible. For example, one data source might report earnings on a financial year basis while the other uses calendar year reporting. This would need to be resolved before linking and analysis can occur.
For more information on metadata, there are references listed at the end of this sheet.
Selecting which fields to use for linking
The main requirement when selecting which fields to use for linking is to ensure that they exist on each of the datasets being linked. Other considerations include the quality of that data, such as whether the data contains any errors or missing information. These may be caused by, for example, variations in spelling (Smith and Smyth), incomplete information or spelling errors (e.g., is ‘Ray’s Burgers’ the same business as ‘Roy’s Burgers’?).
Differences in the fields on different datasets often arise as a result of factors in the data collection phase. Errors may occur if information is supplied by a relative rather than the person themselves, as could be the case, for example, for schools enrolment data or hospital admissions.
Varying levels of quality between datasets often depend on the relative importance of a particular field for a dataset. For example, in mortality datasets the names are critical for identity resolution reasons and so this field is collected and transcribed very carefully and is, therefore, high quality.
Data cleaning and standardising
The terms ‘data cleaning’ and ‘data standardisation’ refer to the task of transforming the records on each dataset into a format that allows them to be linked with other datasets.
The key aim of data cleaning and standardising is to ensure all the data being linked is consistent and uniform, so the linking software can work effectively.
Most datasets contain some incomplete, out-of-date or differently formatted information. Computerised records can contain errors because, for example, information has been provided or recorded incorrectly.
The most common data inconsistencies involve variations in spelling of names, such as nicknames (e.g., Rob and Robert), formats of date of birth, data coding and missing information. Techniques used to resolve these inconsistencies to convert data into standard forms include: editing, standardising, de-duplication and correspondences.
Editing is the identification and treatment of data errors and anomalies. For example, editing may include the removal of an impossible response, such as a birth date in the future and its re-clarification as a missing value.
Where data is missing, sometimes there is enough information available to approximate the data. This is often called ‘data repair’. Data repair should be well documented in terms of the decisions arrived at and data used to make the repairs.
This may involve accessing additional information from previous data collections similar to the one being linked, to check for inconsistencies and help to inform decisions about missing information. An example of data repair would involve changing a postcode to match suburb and street information.
Standardising is the formatting of data items so they are consistently represented in all of the datasets. For example, dates can be represented in different formats such as, DD/MM/YYYY or MM/DD/YYYY. One format should be selected and employed across all of the datasets for that project.
De-duplication is removing duplicates from a dataset. For example, when a record incorrectly appears more than once in a dataset with exactly the same data item value, one copy should be retained, and the others should be removed. Alternatively, the same unit may appear more than once in the same dataset but with different values for some of the data items. Sorting and ordering the datasets will highlight these cases. A set of rules should be developed to treat such duplicates in a consistent manner, such as how to decide which records to keep.
Correspondence involves creating a consistent coding classification across all datasets. A sound understanding of the data is required to produce the best correspondence. Table 1 shows how marital status could be coded in two different datasets.
Dataset 2 could be used as the standard and the first dataset would be altered to be consistent with that coding.
| Dataset 1 | Dataset 2 |
|---|---|
| 1. Never Married | 1. Never Married |
| 2. Currently Married | 2. Currently Married |
| 3. Separated | 3. No Longer Married |
| 4. Divorced | |
| 5. Widowed |
Secure data transfer
When transferring data between organisations, secure data transfer considerations are essential to preserve privacy. They include consideration of the format, method and encryption.
Box 1 shows an example of secure data transfer, based on Statistics New Zealand’s key steps in encrypted-DVD courier delivery – a common method of data transfer for large datasets.
Email transfer is often only suitable for small datasets. More secure email systems are being developed that could provide better options for consideration in the future.
| 1. Media creation and encryption | The data custodian extracts information from their systems and copies it to a CD/DVD using an encrypted format. |
|---|---|
| 2. Handover to courier | The data custodian hands the media to the courier, with the name and address of the recipient (the organisation doing the linking). |
| 3. Delivery | A key contact person from the linking organisation receives the data and signs for its receipt. All transactions must be recorded. |
| 4. Transfer to IT secure facilities | The data should be personally carried by the key contact person to the relevant secure IT facilities of the linking organisation. |
| 5. Place in safe storage | The data transfer and the database loading are completed and stored securely. |
| 6. Disposal | Once transfer is completed, the linking organisation destroys the media (i.e., shredding of DVDs, deletion of back-up files, and for very sensitive information at high risk, degaussing (demagnetisation)). |
| 7. Confirmation to data custodian | The linking organisation informs the data custodian when the data transfer is successful (or not). |
| 8. Preliminary checks of the data | Once the data has been received, the linking organisation checks the received data to confirm it is fit-for-purpose. |
Data quality
- Australian Bureau of Statistics 2011, Information Paper: Quality Management of Statistical Outputs Produced from Administrative Data, Cat. no. 1522.0, Australian Bureau of Statistics, Canberra.
- Australian Institute of Health and Welfare Metadata Online Registry (METeOR), metadata, quality statements and National Data Dictionaries http://meteor.aihw.gov.au
Data cleaning and standardising
- Gill, L. 2001, ‘Methods for Automatic Record Matching and Linkage and their Use in National Statistics’, National Statistics Methodological Series, No. 25, Oxford University, Norwich.
Deterministic linking involves the exact matching of information on different records across the datasets being combined for a linking project.
The simplest form of deterministic linking uses a unique identifier, such as an Australian Business Number or a social security number, to determine if the records refer to the same entity. (An entity may be a person, household, organisation or locality.)
This is also called ‘exact linking’ because the identifier either matches or does not match. This means that if the unique identifier contains any errors, the matches will not be found because the identifiers must be identical on all the datasets being linked.
If it is the case that the unique identifiers may be unreliable for linking purposes, there are a number of other options available. One is to instead use probabilistic linking or other possible approaches could include variations of deterministic linking, such as ‘stepwise deterministic linking’ and ‘rules-based linking’. These techniques use other information on the records to overcome deficiencies in the quality of the unique identifier.
If a unique identifier is not available, or is not of sufficient quality, it is possible to create a proxy, often referred to as a linkage key.
Key Terms
- Confidentiality – the legal and ethical obligation to maintain and protect the privacy and secrecy of the person, business, or organisation that provided their information.
- Content data – the term used for the administrative or clinical information on a record (such as medical condition, income, educational attainment), as opposed to identifying information (such as name and address).
- Identifier – for the purpose of data linking, an identifier is information that establishes the identity of an individual or organisation. For example, for individuals it is often name and address. Also see Unique identifier.
- Unique identifier – a number or code that uniquely identifies a person, business or organisation, such as passport number or Australian Business Number (ABN).
Creating a linkage key
A linkage key is a code created using a combination of identifying information on each record, such as name, address and date of birth (see Table 1 for an example).
The linkage key usually replaces identifiers on the linked record. If the records in the linked dataset are de-identified (by removing name and address), this helps to protect the identity of the people or organisations in the new dataset.
However, this does not necessarily ensure privacy protection. Even without name and address it may still be possible to recognise a person or organisation, through a set of unusual characteristics in the linked dataset. For example, small-area data (e.g., a suburb) showing a 17-year-old widow with four children could be recognisable to someone living in that area. Therefore, further confidentiality techniques need to be applied before releasing the data.
The Confidentiality Information Series provides more information on privacy and confidentiality.
Table 1 shows how a 12 character key might be built using:
- the second, third and fifth letters of a person’s last name, second and third letter from a person’s first name
- the second, fourth, sixth and seventh numbers from a person’s date of birth (DD/MM/YYYY)
- gender (male is 1 and female is 2)
- the second and third numbers of the postcode.
| Name | Date of birth | Gender | Postcode |
|---|---|---|---|
| John Smith | 12/05/1970 | Male | 5623 |
| Linkage key = MIHOH2597162 |
As with the unique identifier, if there is an error or missing information on the records, the linkage key may not match exactly and therefore the records will not be linked.
As linkage keys use identifiers in their creation, technically they could be reconstructed, thereby identifying people in the dataset. Therefore, encryption of the key is recommended as an additional safety measure to avoid the risk of identification or re-identification.
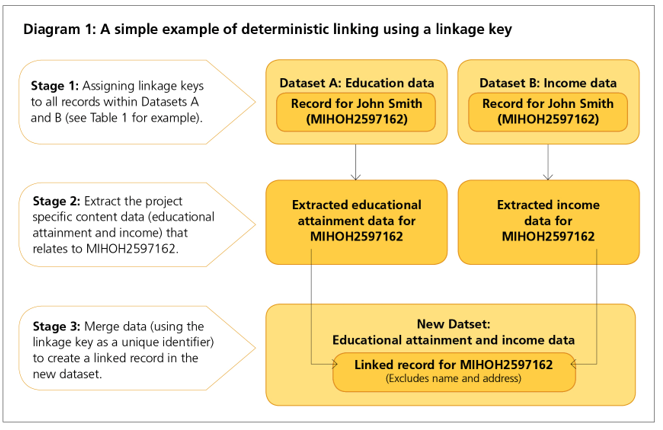
An example of deterministic linking using a linkage key
Stage 1: Assigning linkage keys to all records within datasets A and B. This example uses a linkage key (based on Table 1) for a project looking at educational attainment and earnings, by age and sex.
Stage 2: Extracting the content data and unique identifier. In this example, the linkage key (MIHOH2597162) identifies the records that refer to the same person, in this case John Smith.
Stage 3: Merging to create a linked record. Using the linkage key, only the information required for the project (highest educational attainment, income, sex and age) is extracted from each record and merged into a new linked record (now known by the identifier MIHOH2597162) in the new dataset. (See Diagram 1)
- Australian Institute of Health and Welfare and Australian Bureau of Statistics 2012, National best practice guidelines for data linkage activities relating to Aboriginal and Torres Strait Islander people, AIHW Cat. no. IHW 74, AIHW, Canberra.
- Australian Institute of Health and Welfare 2011, ‘Comparing an SLK-based and a name-based data linkage strategy: an investigation into the PIAC linkage]’, Data linkage series, No. 11. Cat. no. CSI 11, AIHW, Canberra.
- Australian Institute of Health and Welfare: Karmel, R. 2005, ‘Data linkage protocols using a statistical linkage key’, Data linkage series, No. 1. Cat. no. CSI 1, AIHW, Canberra.
- Bass, J. and Garfield, C. 2002, ‘Statistical linkage keys: How effective are they?’ Proceedings of Symposium on health data linkage, Public Health Information Development Unit, held March 20-21 2002, Sydney, pp. 40-45.
- NCSIMG 2004, Statistical Data Linkage in Community Services Data Collection, AIHW, Canberra.
Probabilistic linking is a method for combining information from records on different datasets to form a new linked dataset.
It has been described as a process that attempts to link records on different files that have the greatest probability of belonging to the same person/organisation.
Whereas deterministic (or exact) linking uses a unique identifier to link datasets, probabilistic linking uses a number of identifiers, in combination, to identify and evaluate links.
Probabilistic linking is generally used when a unique identifier is not available or is of insufficient quality.
The method derives its name from the probabilistic framework developed by Fellegi and Sunter (1969) and requires sophisticated software to perform the calculations. References at the end of this sheet provide more information about linking algorithms.
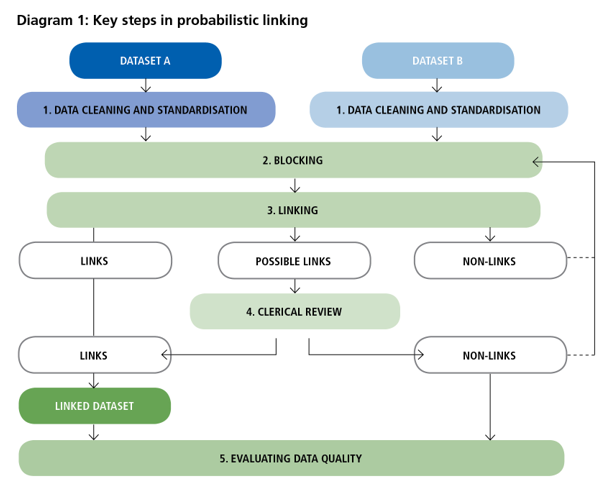
The key steps of probabilistic linking (as shown in Diagram 1) are:
- Data cleaning and standardisation
- Blocking
- Linking
- Clerical review
- Evaluating data quality
Key Terms
- Blocking – divides datasets into groups, called blocks, in order to reduce the number of comparisons that need to be conducted to find which pairs of records should be linked. Only records in corresponding blocks on each dataset are compared, to identify possible links.
- Fields – types of information, such as name, address, date of birth, on the records in datasets.
- Linked dataset – the result of linking different datasets is a new dataset whose records contain some information from each of the original datasets.
- Links – records that have been combined after being assessed as referring to the same entity (i.e., person/family/organisation/region).
- Unique identifier – a number or code that uniquely identifies a person, business or organisation, such as passport number or Australian Business Number (ABN).
Key steps in probabilistic linking
1. Data cleaning and standardisation
See Preparing for Linking in this information series.
2. Blocking
Data linking involves a large number of record comparisons. Ideally, every record on Dataset A is compared with each one on Dataset B to find which record pairs are most likely to be links. However, if every record is compared between two datasets containing 100 000 records each, this would require 10 billion comparisons. Even using advanced computer power, this would take a long time to perform.
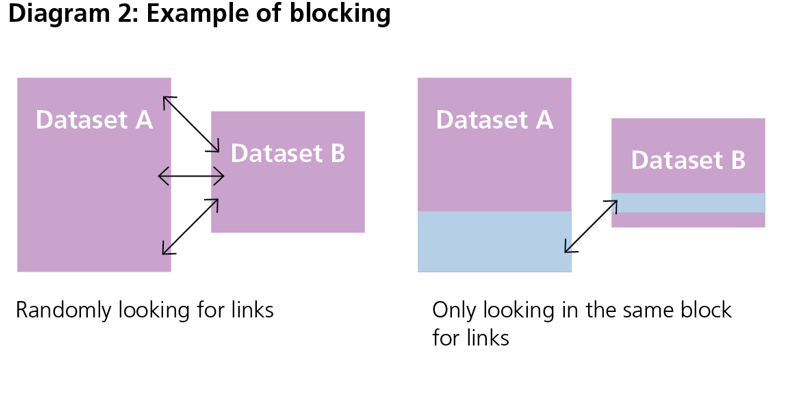
As a way to save time, ‘blocking’ is used to reduce the number of record comparisons required to find potential record pairs.
Blocking is similar to sorting a basket of socks into like colours before trying to locate the pairs. See Diagram 2.
For example, by using gender for blocking, only records with the same sex (males or females) are compared to each other, which usually cuts in half the number of comparisons required.
However, gender is not overly useful for blocking as it only separates the dataset into two large blocks, so a lot of comparisons are still required. Ideally, a blocking strategy should result in small, equal-sized blocks on each dataset.
For example, using month of birth would result in 12 blocks (one for each month) and be expected to have a fairly even number of records in each block. A common strategy is to keep the block sizes as small as possible and run multiple blocking passes.
Blocking Passes
Sometimes links are missed because the information in the selected blocks was missing or incorrectly recorded.
The more blocking passes used, the more links are likely to be identified, but there will generally be diminishing returns on subsequent passes.
Devising a blocking strategy
Although all the fields that are common to both datasets could potentially be used to compare the records, some are more appropriate than others, as discussed in Table 1.
Selecting which fields will be used for blocking and linking should be established before the process starts. It is good practice to plan and document the blocking strategy used for the project.
Blocking often requires some trial and error to determine the best outcome. References at the end of this sheet provide more information on blocking.
| Surnames | Standardising makes this field more useful for linking and blocking. Sometimes parts of the surname and first name (e.g., first two letters of each) may be used as a blocking variable. Note that name changes can occur as a result of marriage and divorce and sometimes surnames and first names are swapped around. Spelling variations can result from errors during recording or transcription. |
|---|---|
| First names | Inconsistencies can result when both nicknames and formal names are used interchangeably, which can cause discrepancies between data sources. |
| Gender | Gender is not overly useful for blocking as it only separates the datasets into two large blocks. Gender is often good for linking as it is generally well reported and unlikely to change during a person’s lifetime. |
| Birth date | Birth month and birth day are usually reliable because they do not change over a person’s lifetime and are usually well reported. If age is collected, it can be checked against birth year for consistency. There may be different date formats (e.g., MM/DD/YYYY or DD/MM/YYYY) which can be addressed by standardisation. Transcription errors may occur when digits are accidentally transposed. Blocking often uses month and year aggregated, rather than the date of birth. |
| Age | Age may be checked against birth year, if available. Age groups may be used as blocks. It is not recommended that age be used in the same blocking pass as birth date because there is a direct relationship between the two fields. |
| Address | As with birth dates, there can be formatting differences in address records, so these generally require standardising. People may change address and sometimes use postal address and street address interchangeably, which affects its usefulness. However, address can still be useful for confirming matches. When address is used in combination with other non-geographical blocks, there is still a chance of identifying links even if people have moved address. For blocking, it is often useful to use an aggregated form of address, such as the suburb or postcode. |
3. Linking
Linking involves a number of steps including assigning field probabilities and using these to calculate field and composite weights. The weights reflect the similarities of each pair of records and provide a way to decide whether they are links, or not.
Calculating probabilities
Each linking field (e.g., name, address, date of birth) on a record has two probabilities associated with it. They are called the ‘m’ and ‘u’ probabilities.
The m probability is the likelihood of the field values agreeing on a pair of records, given the records refer to the same entity (e.g., person, organisation).
It can be thought of as follows: if two different datasets contain records that refer to the same person, what would prevent the information in those records from agreeing? The answer is usually errors in spelling or missing information.
Therefore, the m probability reflects the reliability of the field, and is calculated as 1 minus the error rate of the field. For example, most people report their gender consistently over time and on different datasets, so the m probability is close to 1 (0.95 in the example on the next page). Address, however,may only have an m probability of 0.7 because different datasets can have different addresses for the same person because they may have moved house.
The probabilistic linking software is used to produce estimates for the m probability. These estimates may be based on prior knowledge of the datasets or similar linking projects, through the identification of a large number of linked and non-linked records that ‘train’ the software, or by using the EM (Expectation-Maximisation) algorithm (see Samuels, 2012 for more information).
The u probability is the likelihood that the field values on two records will agree, given the two records refer to different entities.
It is essentially a measure of how likely two fields on different records will agree by chance. Another way to think of this is: given two records belong to two different people, what is the probability that they will agree anyway?
The u probability is often estimated by 1/n (where n is the number of possible values). For gender, there are two possible values (male or female) so the u probability for gender is ½ (0.5). For month of birth, the u probability can be estimated as 1/12 (0.08).
Calculating the field weights
Using the m and u probabilities, the probabilistic linking software generates an estimate of how closely the relevant fields agree on each record pair being compared. This is called a field weight.
In practice, field weights may be modified to allow for partial agreement, such as a minor difference in spelling (e.g., Block vs Black in the example in Box 1).
This is achieved using a ‘string comparator’ to generate a lower, but still positive agreement field weight depending on the specified degree of similarity. Some string comparator options include:
- Exact match where the fields either agree or they do not − no adjustment is made to the field weight (e.g., gender).
- Exact match but the weight is modified so that rarer values are given higher weights than more common values when they agree (e.g., country of birth).
- Approximate string comparison (e.g., name) where the weight depends on the number of characters that differ, allowing for misspellings and poor handwriting (see Winkler, 1990).
For more information about m and u probabilities and field weights, refer to Fellegi and Sunter (1969).
For each possible record pair, the field weights are summed to produce an overall weight − the composite weight. The higher the composite weight, the more likely that both records refer to the same entity. Box 1 provides a highly simplified example of this process.
Determining links based on threshold cut-offs
The composite weight for each record pair is compared to the cut-off threshold. If the composite weight is above the cut-off, the record pair is deemed to be a link. If the composite weight is below the cut-off, the record pair is deemed not to be a link. Sometimes two cut-off thresholds (upper and lower) are used.
A key feature of this methodology is the ability to rank all of the possible links and then, using an ‘optimal threshold’ algorithm (see Christen, 2012), assign the link to the most optimal record pair based on how well the records match.
Various manual and automated methods are available to determine thresholds based on the distribution of the composite weights for the linked records.
4. Clerical Review
Clerical review is a useful tool to manually assess those records without a designated link/non-link status and to examine records close to the thresholds to check if they are links.
However, clerical review is time-consuming and resource-intensive. To minimise the number of records that need to be reviewed, it is necessary to ensure that threshold values are appropriate and the linking software is operating as efficiently as possible. For more information on clerical review see Guiver (2011).
5. Evaluating data quality
This is covered in Preparing for Linking and Linked Data Quality
The following example is taken from the Statistics New Zealand Data Integration Manual.
It looks at two records on two different datasets to see whether they are a match and, therefore, should be linked.
| Field | Record A | Record B |
|---|---|---|
| Name | Jon Block | John Black |
| Date of birth | 23-11-65 | 23-11-63 |
| Sex | M | M |
| Address | 89 Molesworth Street | 112 Hiropi Street |
The linking software assigns m and u probabilities for each field (shown below) which range between 0 and 1.
(The calculation of the agreement field weight is log2[m/u]. The disagreement field weight is log2([1 − m]/[1 −u]).)
| Field | m probability | u probability | Agreement field weight | Disagreement field weight |
|---|---|---|---|---|
| Name | 0.95 | 0.01 | 6.57 | −4.31 |
| Date of birth | 0.9 | 0.01 | 6.49 | −3.31 |
| Sex | 0.95 | 0.5 | 0.93 | −3.32 |
| Address | 0.7 | 0.01 | 6.13 | −1.72 |
The fields on the two records are compared (see table below). Field weights with positive values indicate that fields agree, while negative values indicate disagreement. In this example, the field weight of −1.72 indicates that the records do not agree on address.
For simplicity, this example assumes no partial field agreement, although in practice, ‘Jon’ and ‘John’ are sufficiently similar that there would probably be some sort of adjustment to the field weights to take account of this, resulting in a lower, but still positive, agreement weight.
| Field | File A | File B | Agreement? | Field weight |
|---|---|---|---|---|
| Name | Jon Block | John Black | No | −4.31 |
| Date of birth | 23-11-65 | 23-11-63 | No | −3.31 |
| Sex | M | M | Yes | 0.93 |
| Address | 89 Molesworth Street | 112 Hiropi Street | No | −1.72 |
| Composite weight (sum of field weights) | −8.41 |
The field weights are summed: (−4.31) + (−3.31) + (0.93) + (−1.72) = −8.41 (= composite weight). As the composite weight in this example is negative (−8.41), the linking process would determine that these records are a non-link.
For more information, see Statistics New Zealand, Data Integration Manual, 2006, pp.36-44.
Probabilistic linking theory
- Fellegi, I. and Sunter, A. 1969, ‘A Theory for Record Linkage’, Journal of the American Statistical Association, Vol.64, no.328, pp. 1183-1210.
Linking (including m and u probabilities)
- Christen, P. 2012, Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection, Springer, Canberra.
- Herzog, T.N., Scheuren, F.J. and Winkler, W.E. 2007, Data quality and record linkage techniques, Springer, New York.
- Jaro, M. 1995, ‘Probabilistic Linkage of Large Public Health Data Files’, Statistics in Medicine, Vol. 14, pp. 491-498.
- Samuels, C. 2012, ‘Using the EM Algorithm to Estimate the Parameters of the Fellegi-Sunter Model for Data Linking research paper’, Methodology Advisory Committee Paper, Cat. no. 1352.0.55.120, Australian Bureau of Statistics, Canberra.
- Statistics New Zealand 2006, Data Integration Manual, Statistics New Zealand, Wellington.
- Winkler, W.E. 1990, ‘String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage’, Proceedings of the Section on Survey Research Methods, American Statistical Association, pp. 354-359.
Clerical review
- Guiver, T. 2011, ‘Sampling-Based Clerical Review Methods in Probabilistic Linking’, Methodology Research Papers, Cat. no. 1351.0.55.034, Australian Bureau of Statistics, Canberra.
- Bishop, G. and Khoo, J. 2007, ‘Methodology of Evaluating the Quality of Probabilistic Linking’, Methodology Research Papers, Cat. no. 1351.0.55.018, Australian Bureau of Statistics, Canberra.
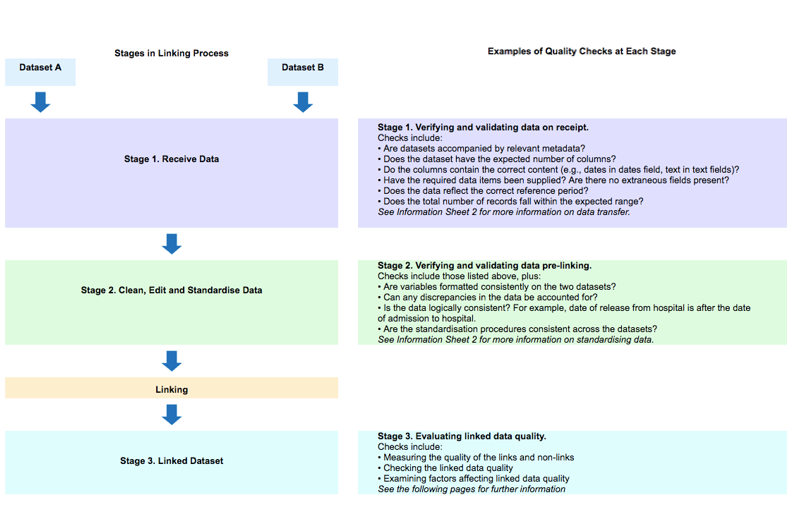
Evaluating linked data quality is a key component of the linking process and essential for any subsequent analysis that uses the linked datasets. A comprehensive understanding of the linked data is built through the measurement, assessment and documentation of the linked record pair quality.
Data quality assessment occurs in three stages. Stage 1 is when the data is received, Stage 2 when the data is cleaned, edited and standardised, and Stage 3 occurs after the data is linked. See Diagram 1.
Stages 1 and 2 are covered in Preparing for Linking. Stage 3 is covered on this page.
For more information on data quality and sound data management practices, see Brackstone (1999) and the National Statistical Service website.
Key Terms
- False links – records that were incorrectly linked and do not refer to the same entity. See Box 1.
- Fields – types of information, such as name, address, date of birth, on the records in datasets.
- Links – combined record pairs assessed as referring to the same entity (i.e., person/family/organisation/region).
- Matches – record pairs that actually refer to the same entity (e.g., person/family/organisation/region).
- Metadata – provides data users with information about the purpose, processes, and methods involved in the data collection; from design through to communication.
Evaluation of linked data quality
Evaluation of linked data quality requires a number of assessments and techniques. To do this, it is important to understand the difference between a match and a link.
A match is a pair of records that refer to the same entity (e.g., person or organisation), whereas a link is a pair of records combined by the linkage process irrespective of whether the records refer to the same entity.
Data quality measures calculate the number of records which were correctly linked (i.e., refer to the same entity), and which records were missed. Prior to analysis, it is important to consider and assess the factors that may have influenced the linked data quality.
Measuring the quality of the links
Ideally, the set of links will be identical to the set of matches. However, this is not usually the case as there may be records without a match or a linking error may occur. See Box 1.
Some of the measures used to check the quality of the links involve considerable statistical expertise. These include evaluating the accuracy, specificity, sensitivity (match rate), precision (link accuracy), false negative rate and the false positive rate. Refer to Box 2 and Christen & Goiser (2007) for more information on the definition and calculation of these measures.
Measures which rely on knowing the number of records that do not have a match (i.e., are a true negative non-link) can be difficult to calculate. Of the techniques noted above, the accuracy, specificity, false negative rate and the false positive rate measures are included in this category.
More commonly, measures based on the total number of matches that are linked (i.e. true positive links) are used. These measures include match rate and link accuracy.
The match rate is defined as:
Match rate = number of true positive links / total matches
The match rate measures the proportion of matches linked (i.e., the set of record pairs, which refer to the same entity). For example, correctly linking all matches would mean the match rate would be 100%. However, calculation of the match rate is difficult if the total number of matches is unknown.
Link accuracy is the proportion of links that are matches (i.e., the proportion of links which are correct). To measure this, an estimate of the number of links that are matches should be undertaken.
Link accuracy = number of true positive links / total links
For example, if 6000 out of 8000 links are correct, the link accuracy is 75%.
Box 1: Classification of matches and links
There are four classifications following the linking process. Records correctly assigned a link status are:
- True positive link – records which refer to the same entity and have been correctly linked.
- True negative link – records which do not have a match and are correctly classified as a non-link.
There are two types of linking errors:
- False positive link – records that have been linked, but do not belong together (also known as false links).
- False negative link – records that have not been linked, but do belong together (also known as missed links or missed matches.
Link Status
| MATCH | NON-MATCH | ||
|---|---|---|---|
| LINK | True positive link (matches that are linked) | False positive link (non-matches that are linked) | Total links |
| NON-LINK | False negative link (matches that are not linked) | True negative non-link (non-matches that are not linked) | Total non-links |
| Total matches | Total non-matches | Total records pairs |
An example of a false positive link
Twin sisters living in the same house with the same initials and surname may have their records incorrectly paired with each other because their linking characteristics are so similar. If the linking software used surname, initials, address, sex and date-of-birth to determine the matches, it could assess their records as a ‘link’ because of the high level of agreement between the linkage fields.
A description of a false negative link
Even if two records on different datasets belong to the same person, the linking process may not identify them as links if:
- there are errors in the source data (such as misspellings of name, address) and/or
- the information changes over time (e.g., if a person changes their name after marriage, the linking software cannot tell if Jane Smith on one dataset and Jane Barnett on another are the same person, if using only name to match).
Additional approaches to checking linked data quality
Prior to analysis, there are a number of additional checks used to assess the quality of a linked dataset. This is to ensure any limitations or issues with the linked data are taken into account during analysis.
Additional checks include comparing linked datasets, clerical assessment, comparing the expected number of links with the actual number of links, and assessing discrepancies in the representation of sub-groups.
There are other more complex approaches, such as simulation-based methods, to assess linkage quality. For more information, refer to Winglee, Valliant and Scheuren (2005).
1. Comparing linked datasets
Results are compared from two separate linking methods applied to the same datasets. This may involve comparing a linked dataset with a ‘gold standard file’ or ‘truth file’ (where available) to assess the quality of the linkage strategy. For further information, see Australian Bureau of Statistics (2013).
2. Clerical assessment
Clerical assessment can be undertaken post linkage to check the quality of the link status assigned to the records. Checking link quality involves a review, usually manual, of the linked records. It is a time consuming and subjective process.
Clerical assessment is different to clerical review as it examines the quality of the link following the linkage process, rather than determining if the records should be a link. For more information, see AIHW and ABS (2012).
3. Comparing the expected number of links with the actual number of links
An initial assessment of the two source datasets may yield an estimate of the number of matches. A simplified example is where a dataset containing 3000 records is known to be a subset of a dataset with 5000 records. In such a case, the estimated number of linked records on the new dataset is 3000. Therefore, if the number of links on the new dataset were significantly less than expected, this would be cause for investigation.
This method is particularly useful if one dataset is a subset (or near subset) of another, e.g., linking an administrative dataset to a census. However, even in cases where the overlap between datasets is quite small, an accurate estimate of this overlap can often be calculated.
4. Assessing discrepancies in the representation of sub-groups
Checking the characteristics of the linked dataset also provides scope for highlighting any population groups that may have been over or under represented.
Some sub-groups can be hard to correctly link. For example, young adults are more mobile, making geographic fields less reliable and children often have uniform or “not applicable” values on a number of fields (such as education, qualification, occupation, marital status). A linked dataset may be under-represented on younger individuals as a result. Refer to Bishop (2009) and Wright, Bishop and Ayre (2009).
When assessing these characteristics it is useful to consider the key factors that have influenced the linked dataset.
| Accuracy rate | Accuracy rate is the proportion of all record pair comparisons that are true positive links or true negative links. The denominator for this rate is the number of all record pair comparisons, while the numerator is the number of record pairs that are correctly classified as true matches or false matches. |
|---|---|
| False-negative rate | False-negative rate is the proportion of all record pairs belonging to the same individuals or entities that are incorrectly assigned as non-links. |
| False-positive rate | False-positive rate is the proportion of all record pairs belonging to two different individuals or entities that are incorrectly assigned as links. |
| Precision (link accuracy) | Precision (Link accuracy) is the proportion of all classified links that are true links as opposed to classified links that are false links. It is calculated by dividing the number of links that are ascertained as true, by the total number of classified links. |
| Sensitivity (match rate) | Sensitivity (match rate) is the proportion of all records in a file or database with a match in another file that were correctly accepted as a link. |
| Specificity or true-negative rate | Specificity or true-negative rate is the proportion of all records on one file or database that have no match in the other file that were correctly not accepted as a link. |
* Sourced from Australian Institute of Health and Welfare (AIHW) and Australian Bureau of Statistics (ABS) 2012. Also see Christen and Goiser 2007.
Factors affecting linked data quality
A record may be missed or a link error may occur (a ‘false link’) for three main reasons.
First, the source data may contain missing or incorrect values on key linking fields. Poor quality data used to link the records can lead to missed links, or records linked to the wrong record.
The source data should be standardised prior to linking, to correct as much as possible typographical errors and out-of-date information. For more information and examples, refer to the CHeReL Quality Assurance report (2013).
Improving the source data quality will reduce the number of missed matches and thereby improve the quality of the linked dataset. For more information on editing and standardising,
Second, a decision point in the linking process is around the trade-off between link accuracy and match rate. A strategy aimed at producing high link quality usually comes at a cost of a reduced number of total links.
This trade-off may be influenced by data availability. For example, as discussed above, there is often limited information available relating to young persons. As a result, there may be a lower degree of certainty regarding the linkage. Therefore, only accepting links that have a high degree of certainty may lead to the linked dataset containing less linked records relating to young persons.
Third, the linking strategy influences the data quality through the blocking strategy used (e.g., the quality of the blocking fields used and the number of passes run), clerical review (such as setting threshold cut-offs) and, if applicable, the quality of the linkage keys created.
For more information on how the linkage strategy affects the quality of the linked data, refer to Bishop and Khoo (2007), Richter, Saher and Campbell (2013) and Australian Institute of Health and Welfare (2011).
Using documentation to improve quality
Documentation is important, as it collates and enhances an understanding of the linked data, including any factors influencing the quality of the data, prior to analysis.
Data linking projects require the documentation of every stage to allow for relevant evaluation and application in future projects. This is particularly useful when different linking strategies are utilised to assess the quality of the linked data.
Documentation also provides the analyst with a more comprehensive understanding of the linked data, providing context around how it may or may not be used for analytical purposes.
Documentation includes:
- the context and quality of the source data, including metadata statements
- risks to confidentiality and how the risks were managed (refer to the Confidentiality Information Series)
- how data has been edited and standardised before linking
- the linking method
- techniques used to overcome issues and/or problems and
- results and findings from evaluation and quality assessments.
- Australian Bureau of Statistics 2009, ABS Data Quality Framework, Cat. no. 1520.0, ABS, Canberra.
- Australian Bureau of Statistics 2013, ‘Assessing the Quality of Linking School Enrolment Records to 2011 Census Data: Deterministic Linkage Methods’,Cat. no. 1351.0.55.045, ABS, Canberra.
- Australian Institute of Health and Welfare 2011, ‘Comparing an SLK-based and name-based data linkage strategy: an investigation into the PIAC linkage’, Data linking series,No. 11 Cat. no. CSI 11, AIHW, Canberra.
- Australian Institute of Health and Welfare (AIHW) and Australian Bureau of Statistics (ABS) 2012, National Best Practice Guidelines for Data Linkage Activities Relating to Aboriginal and Torres Strait Islander People, AIHW Cat. no. IHW 74, AIHW, Canberra.
- Bishop, G. 2009, ‘Assessing the Likely Quality of the Statistical Longitudinal Census Dataset’, Methodology Research Papers, Cat. no. 1351.0.55.026, ABS, Canberra.
- Bishop, G. and Khoo, J. 2007, ‘Methodology of Evaluating the Quality of Probabilistic Linking’, Methodology Research Papers, Cat. no. 1351.0.55.018, ABS, Canberra.
- Brackstone, G. 1999, ‘Managing data quality in a statistical agency’, Survey Methodology, December 1999, Vol. 25, No. 2, pp. 139-149.
- CHeReL, Quality Assurance, http://www.cherel.org.au/quality-assurance, viewed November 2013.
- Christen, P. and Goiser, K. 2007, ‘Quality and complexity measures for data linkage and deduplication’, in Guillet, F. and Hamilton, H. editors, Quality Measures in Data Mining, Vol. 43 of Studies in Computational Intelligence, Springer, pp. 127-151.
- National Statistical Service 2011, Confidentiality Information Series, National Statistical Service, Canberra.
- Richter, K., Saher, G. and Campbell, P. 2013, ‘Assessing the quality of linking migrant settlement records to 2011 Census data’, Cat. no. 1351.0.55.043, ABS, Canberra.
- Winglee, M., Valliant, R. and Scheuren, F. 2005, ‘A Case Study in Record Linkage’, Survey Methodology, Cat. no. 12-001, Statistics Canada.
- Wright, J., Bishop, G. and Ayre, T. 2009, ‘Assessing the Quality of Linking Migrant Settlement Records to Census Data’, Methodology Research Papers, Cat. no. 1351.0.55.027, ABS, Canberra.